What these folks do is legal. It’s called tax avoidance, and the more money you have, the harder you and your accountants will work, and the better at it you’ll be. There is an entire industry built around tax avoidance.
From www.ccPixs.com
Though I want to disapprove of these people, it does occur to me that most of us do not willingly pay taxes that we are not required to pay. It’s not like I skip out on deducting my charitable giving or my mortgage interest, or using the deductions for my kids. I’m legally allowed those deductions and I use them.
So what is wrong with what Trump and Romney do?
One answer is “nothing.” I think that’s not quite the right answer, but it’s close. Yes, just because something is legal does not mean that it’s moral. But where do you draw the line here? Is it based on how clever your accountants had to be to work the system? Or how crazy the hoops you jumped through were to hide your money? I’m not comfortable with fuzzy definitions like that at all.
What is probably immoral, is for a rich person to try to influence the tax system to give himself more favorable treatment. But then again, how do you draw a bright line? Rich people often want lower taxes and (presumably) accept that that buys less government stuff and/or believe that they should not have to transfer their wealth to others. That might be a position that I don’t agree with, but the case for immorality there is a bit more complex, and reasonable people can debate it.
On the other hand, lobbying for a tax system with loopholes that benefit them, and creating a system of such complexity that only the wealthiest can navigate it, thus putting the tax burden onto other taxpayers, taxpayers with less money, is pretty obviously immoral. Well, if not immoral, definitely nasty.
I’ve been bouncing around just at the edge of my 2016 presidential campaign overload limit, and the other night’s debate and associated post-debate blogging sent me right through it.
Yes, I was thrilled to see my preferred candidate (Hermione) outperform the other candidate (Wormtail), but all the post-debate analysis and gloating made me weary.
Then, I thought about the important issues facing this country, the ones that keep me up at night worrying for my kids, the ones that were not discussed in the debate, or if they were, only through buzzwords and hand waves, and I got depressed. Because there is precious little in the campaign that addresses them. (To be fair, Clinton’s platform touches on most of these, and Trump’s covers a few, though neither as clearly or candidly as I’d like.)
So, without further ado, I present my list of campaign issues I’d like to see discussed, live, in a debate. If you are a debate moderator from an alternate universe who has moved through an interdimensional portal to our universe, consider using some of these questions:
1.
How do we deal with the employment effects of rapid technological change? File the effects of globalization under the same category, because technological change is a driver of that as well. I like technology and am excited about its many positive possibilities, but you don’t have to be a “Luddite” to say that it has already eliminated a lot of jobs and will eliminate many more. History has shown us that whenever technology takes away work, it eventually gives it back, but I have two issues with that. First, it is certainly possible that “this time it’s different. Second, and more worrisome, history also shows that the time gap between killing jobs and creating new ones can be multigenerational. Furthermore, it’s not clear that the same people who had the old jobs will be able to perform the new ones, even if they were immediately available.
from Wikimedia
This is a setup for an extended period of immiseration for working people. And, by the way, don’t think you’ll be immune to this because you’re a professional or because you’re in STEM. Efficiency is coming to your workplace.
It’s a big deal.
I don’t have a fantastic solution to offer, but HRC’s platform, without framing the issue just as I have, does include the idea of major infrastructure reinvestment, which could cushion this effect.
Bonus: how important should work be? Should every able person have/need a job? Why or why not?
2.
Related to this is growing inequality. The technology is allowing fewer and fewer people to capture more and more surplus. Should we try to reverse that, and if so, how do we do so? Answering this means answering some very fundamental questions about what is fairness that I don’t think have been seriously broached.
from Wikimedia
Sanders built his campaign on this, and Clinton’s platform talks about economic justice, but certainly does not frame it so starkly.
What has been discussed, at least in the nerd blogosphere, are the deleterious effects of inequality: its (probably) corrosive effect on democracy as well as its challenge to the core belief that everyone gets a chance in America.
Do we try to reverse this or not, and if so, how?
3.
from Wikimedia
Speaking of chances, our public education system has been an important, perhaps the important engine of upward mobility in the US. What are we going to do to strengthen our education system so that it continues to improve and serve everyone? This is an issue that spans preschool to university. Why are we systematically trying to defund, dismantle, weaken, and privatize these institutions? Related, how have our experiments in making education more efficient been working? What have we learned from them?
4.
Justice. Is our society just and fair? Are we measuring it? Are we progressing? Are we counting everyone? Are people getting a fair shake? Is everyone getting equal treatment under the law?
from Wikimedia
I’m absolutely talking about racial justice here, but also gender, sexual orientation, economic, environmental, you name it.
If you think the current situation is just, how do you explain recent shootings, etc? If you think it is not just, how do you see fixing it? Top-down or bottom-up? What would you say to a large or even majority constituency that is less (or more) concerned about these issues than you yourself are?
5.
From Wikimedia
Climate change. What can be done about it at this point, and what are we willing to do? Related, given that we are probably already seeing the effects of climate change, what can be done to help those adversely effected, and should we be doing anything to help them? Who are the beneficiaries of climate change or the processes that contribute to climate change, and should we transfer wealth to benefit those harmed? Should the scope of these questions extend internationally?
6.
Rebuilding and protecting our physical infrastructure. I think both candidates actually agree on this, but I didn’t hear much about plans and scope. We have aging:
electric
rail
natural gas
telecom
roads and bridges
air traffic control
airports
water
ports
internet
What are we doing to modernize them, how much will it cost? What are the costs of not doing it? What are the barriers that are getting in the way of major upgrades of these infrastructures, and what are we going to do to overcome them?
Also, which of these can be hardened and protected, and at what cost? Should we attempt to do so?
7.
Military power. What is it for, what are its limits? How will you decide when and how to deploy military power? Defending the US at home is pretty straightforward, but defending military interests abroad is a bit more complex.
DoD photo
Do the candidates have established doctrines that they intend follow? What do they think is possible to accomplish with US military power and what is not? What will trigger US military engagement? Under what circumstances do we disengage from a conflict? What do you think of the US’s record in military adventures and do you think that tells you anything about the types of problems we should try to solve using the US military?
7-a. Bonus. What can we do to stop nuclear proliferation in DPRK? Compare and contrast Iran and DPRK and various containment strategies that might be deployed.
If you’ve spent any time in an energy economics class, you have probably seen a slide that shows the essential equivalency of a carbon tax and a cap-and-trade system, at least with respect to their ability to internalize externalities and fix a market failure. However, if you scratch the surface of the simple model used to claim this equivalency and you realize it only works if you have a good knowledge of the supply and demand curves for carbon emissions. (There are other non-equivalencies, too, like where the incidence of the costs falls.)
The equivalency idea is that for a given market clearing of carbon emissions and price, you can either set the price, and get the emissions you want, or set the emissions and you will get the price. As it turns out, nobody really has a good grip on the nature of those curves, and we live in a world of uncertainty anyway, so there actually is a rather important difference: what variable are we going to “fix” about and which one will “float,” carrying all the uncertainty: the price of the carbon emissions quantity?
I bring this up because today I read a nice blog post by Severin Borenstein which I will reduce to its essential conclusion: A carbon tax is much better than cap-and-trade. He brings up the point above, stating that businesses just are much better able to adapt when they know what the price is going to be, but there are other advantages to a tax.
First, administratively, it is much easier to set a tax than it is to legislate an active and vibrant market into existence. If you’ve lived in the world of public policy, I hope you know that Administration Matters.
Furthermore, legislatures are not fast, closed-loop control systems. They can’t adapt their rules on the fly quickly as new information comes in, and sometimes political windows close entirely, making it impossible make corrections. As a result, the ability to adjust caps in a timely manner is, at best, difficult. This is a fundamentally harder problem then getting people to agree, a priori, on what an acceptable price — one with more than a pinch of pain, but not enough to kill the patient.
So, how did we end up with cap-and-trade rather than a carbon tax? Well, certainly a big reason is the deathly allergy legislatures have to the word “tax.” Even worse: “new tax.” Perhaps that was the show-stopper right there. But it certainly did not help that we had economists (I suspect Severin was not among them) providing the conventional wisdom that a carbon tax and a cap-and-trade system are essentially interchangeable. The latter is not true, unless a wise, active, and responsive regulator, free to pursue an agreed objective is at the controls. So pretty much never.
Short post here. I notice people are writing about self-driving cars a lot. There is a lot of excitement out there about our driverless future.
I have a few thoughts, to expand on at a later day:
I.
Apparently a lot of economic work on driving suggests that the a major externality of driving is from congestion. Simply, your being on the road slows down other people’s trips and causes them to burn more gas. It’s an externality because it is a cost of driving that you cause but don’t pay.
Now, people are projecting that a future society of driverless cars will make driving cheaper by 1) eliminating drivers (duh) and 2) getting more utilization out of cars. That is, mostly, our cars sit in parking spaces, but in a driverless world, people might not own cars so much anymore, but rent them by the trip. Such cars would be much better utilized and, in theory, cheaper on a per-trip basis.
So, if I understand my micro econ at all, people will use cars more because they’ll be cheaper. All else equal, that should increase congestion, since in our model, congestion is an externality. Et voila, a bad outcome.
II.
But, you say, driverless cars will operate more efficiently, and make more efficient use of the roadways, and so they generate less congestion than stupid, lazy, dangerous, unpredictable human drivers. This may be so, but I will caution with a couple of ideas. First, how much less congestion will a driverless trip cause than a user-operated one? 75% as much? Half? Is this enough to offset the effect mentioned above? Maybe.
But there is something else that concerns me: the difference between soft- and hard-limits.
Congestion as we experience it today, seems to come on gradually as traffic approaches certain limits. You’ve got cars on the freeway, you add cars, things get slower. Eventually, things somewhat suddenly get a lot slower, but even then it’s certain times of the day, in certain weather, etc.
Now enter a driverless cars that utilize capacity much more effectively. Huzzah! More cars on the road getting where they want, faster. What worries me is that was is really happening is not that the limits are raised, but that we are operating the system much close to existing, real limits. Furthermore, now that automation is sucking out all the marrow from the road bone — the limits become hard walls, not gradual at all.
So, imagine traffic is flowing smoothly until a malfunction causes an accident, or a tire blows out, or there is a foreign object in the road — and suddenly the driverless cars sense the problem, resulting in a full-scale insta-jam, perhaps of epic proportions, in theory, locking up an entire city nearly instantaneously. Everyone is safely stopped, but stuck.
And even scarier than that is the notion that the programmers did not anticipate such a problem, and the car software is not smart enough to untangle it. Human drivers, for example, might, in an unusual situation, use shoulders or make illegal u-turns in order to extricate themselves from a serious problem. That’d be unacceptable in a normal situation, but perhaps the right move in an abnormal one. Have you ever had a cop the scene of an accident wave at you to do something weird? I have.
Will self-driving cars be able to improvise? This is an AI problem well beyond that of “merely” driving.”
III.
Speaking of capacity and efficiency, I’ll be very interested to see how we make trade-offs of these versus safety. I do not think technology will make these trade-offs go away at all. Moving faster, closer will still be more dangerous than going slowly far apart. And these are the essential ingredients in better road capacity utilization.
What will be different will be how and when such decisions are made. In humans, the decision is made implicitly by the driver moment by moment. It depends on training, disposition, weather, light, fatigue, even mood. You might start out a trip cautiously and drive more recklessly later, like when you’re trying to eat fast food in your car. The track record for humans is rather poor, so I suspect that driverless cars will do much better overall.
But someone will still have to decide what is the right balance of safety and efficiency, and it might be taken out of the hands of passengers. This could go different ways. In a liability-driven culture me way end up with a system that is safer but maybe less efficient than what we have now. (call it “little old lady mode”) or we could end up with decisions by others forcing us to take on more risk than we’d prefer if we want to use the road system.
IV.
I recently read in the June IEEE Spectrum (no link, print version only) that some people are suggesting that driverless cars will be a good justification for the dismantlement of public transit. Wow, that is a bad idea of epic proportions. If, in the first half of the 21st century, the world not only continues to embrace car culture, but doubles down to the exclusion of other means of mobility, I’m going to be ill.
* * *
That was a bit more than I had intended to write. Anyway, one other thought is that driverless cars may be farther off than we thought. In a recent talk, Chris Urmson, the director of the Google car project explains that the driverless cars of our imaginations — the fully autonomous, all conditions, all mission cars — may be 30 years off or more. What will come sooner are a succession of technologies that will reduce driver workload.
So, I suspect we’ll have plenty of time to think about this. Moreover, the nearly 7% of our workforce that works in transportation will have some time to plan.
It’s not a new debate, and though I will get into some specifics of the discussion below, what really resonated for me is how religious and ideological is the belief that corporations just do everything better. It’s not like the WSJ made any attempt whatsoever to list (and even dismiss) counter-arguments to ATC privatization. It’s almost as if the notion that there could be some justification for a publicly funded and run ATC has just never occurred to them.
What both pieces seemed to have in common is a definition of dysfunction that hews very close to “not the outcome that a market would have produced.” That is to say, they see the output of non-market (that is, political) processes as fundamentally inferior and inefficient, if not outright illegitimate. Of course, the outcomes from political processes can be inefficient and dysfunctional, but this is hardly a law of nature.
For my loyal reader (sadly, not a typo), none of this is news, but it still saddens me that so many potentially interesting problems (like how best to provision air traffic control services) break down on such tired ideological grounds: do you want to make policy based on one-interested-dollar per vote or one-interested-person per vote?
I want us to be much more agnostic and much more empirical in these kinds of debates. Sometimes markets get good/bad outcomes, sometimes politics does.
For example, you might never have noticed that you can’t fly Lufthansa or Ryanair from San Francisco to Chicago. That’s because there are “cabotage” laws in the US that bar foreign carriers from offering service between US cities. Those laws are blatantly anti-competitive and the flying public is definitely harmed by this. This is a political outcome I don’t particularly like due, in part, to Congress paying better attention to the airlines than to the passengers. Yet, I’m not quite ready to suggest that politics does not belong in aviation.
Or, in terms of energy regulation, it’s worth remembering that we brought politics into the equation a very long time ago because “the market” was generating pretty crappy outcomes, too. What I’m saying is that neither approach has a exclusive rights to dysfunction.
OK. Let’s get back to ATC and the WSJ piece.
In it, the WSJ makes frequent reference to Canada’s ATC organization, NavCanada, that was privatized during a budget crunch a few years back, and has performed well since then. This is in contrast to to an FAA that has repeated “failed to modernize.”
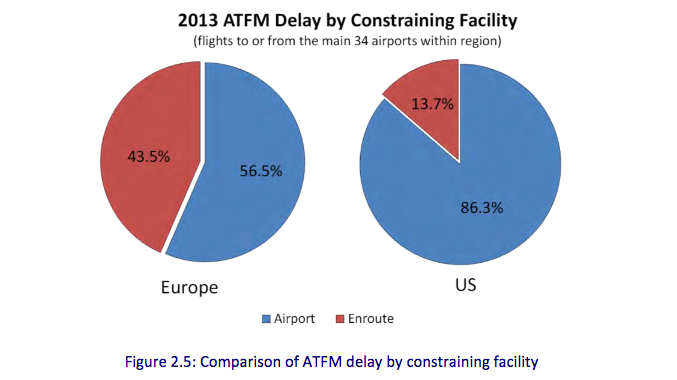
But the US is not Canada, and our air traffic situation is very different. A lot of planes fly here! Anyone who has spent any serious time looking at our capacity problems knows that the major source of delay in the US is from insufficient runways and terminal airspace, not control capabilities per se. That is to say, modernizing the ATC system so that aircraft could fly more closely using GPS position information doesn’t really buy you all that much if the real crunch is access to the airport. If you are really interested, check out this comparison of the US and European ATC performance. The solution in the US is pouring more concrete in more places, not necessarily a revamped ATC. (It’s not that ATC equipment could not benefit from revamping, only that it is not the silver bullet promised.)
Here’s another interesting mental exercise: Imagine you have developed new technology to improve the throughput of an ATC facility by 30% — but the hitch is that when you deploy the technology, there will be diminution in performance during the switchover, as human learning, inevitable hiccups, and the need to temporary run the old and new systems in parallel takes its toll. Now imagine that you want to deploy that technology at a facility that is already operating at near its theoretical maximum capability. See a problem there? It’s not an easy thing.
Another issue in the article regards something called ADS-B (Automatic Dependent Surveillance – Broadcast), a system by which aircraft broadcast their GPS-derived position. Sounds pretty good, and yet, the US has taken a long time to get it going widely. (It’s not required on all aircraft until 2020) Why? Well, one reason is that a lot of the potential cost-savings from switching to ADS-B would come from the retirement of expensive, old primary radars that “paint” aircraft with radio waves and sense the reflected energy. Thing is, primary radars can see metal objects in the sky, and ADS-B receivers only see aircraft that are broadcasting their position. You may have heard in recent hijackings how transponders were disabled by pilot — so, though the system is cool, it certainly cannot alone replace the existing surveillance systems. The benefits are not immediate and large, and it leaves some important problems unsolved. Add in the high cost of equippage, and it was an easy target to delay. But is that a sign of dysfunction or good decision-making?
All of which is to say that I’m not sure a privately run organization, facing similar constraints, would make radically different decisions than has the FAA.
Funding the system is an interesting question, too. Yes, a private organization that can charge fees has a reliable revenue stream and is thus is able to go to financial markets to borrow for investment. This is in contrast to the FAA, which has had a hard time funding major new projects because of constant congressional budget can-kicking. Right now the FAA is operating on an extension of its existing authorization (from 2012), and a second extension is pending, with a real reauthorization still behind that. OK, so score one for a private organization. (Unless we can make Congress function again, at least.)
But what happens to privatized ATC if there is a major slowdown in air travel? Do investments stop, or is service degraded due to cost cutting, or does the government end up lending a hand anyway? And how might an airline-fee-based ATC operate differently from one that ostensibly serves the public? Even giving privatization proponents the benefit of the doubt that a privatized ATC would be more efficient and better at cost saving, would such an organization be as good at spending more money when an opportunity comes along to make flying safer, faster, or more convenient for passengers? How about if the costs of such changes fall primarily on the airlines, through direct equippage costs and ATC fees? Or, imagine a scenario where most airlines fly large aircraft between major cities, and an an upstart starts flying lots of small aircraft between small cities. Would a privatized ATC or publicly funded ATC better resist the airlines’ anti-competitive pressures to erect barriers to newcomers?
I actually don’t know the answers. The economics of aviation are somewhat mysterious to me, as they probably are to you unless your an economist or operations researcher. But I’m pretty sure the Scott McCartney of the WSJ knows even less.